


The tooling is here. Agentic coding systems can generate entire codebases autonomously. But generating code was never the hard part. Any capable model can do that just fine. The harder question is: how do you gain confidence in a system you didn't write and may never read?
What is Confidence?
Confidence is alignment, understanding, and trust.
Normally, when you write and review source code that you have expertise in, you know if it follows the right patterns, makes the right tradeoffs, and does what you need. You can work with it. You can change it. You can fix it. And so can the rest of your team.
However, when you aren’t the one writing or judging the code, you need to outsource expertise. That means building an AI agent orchestration system with confidence as a first principle at every phase.
Two Layers Removed
If you aren't working on the code, what are you working on?
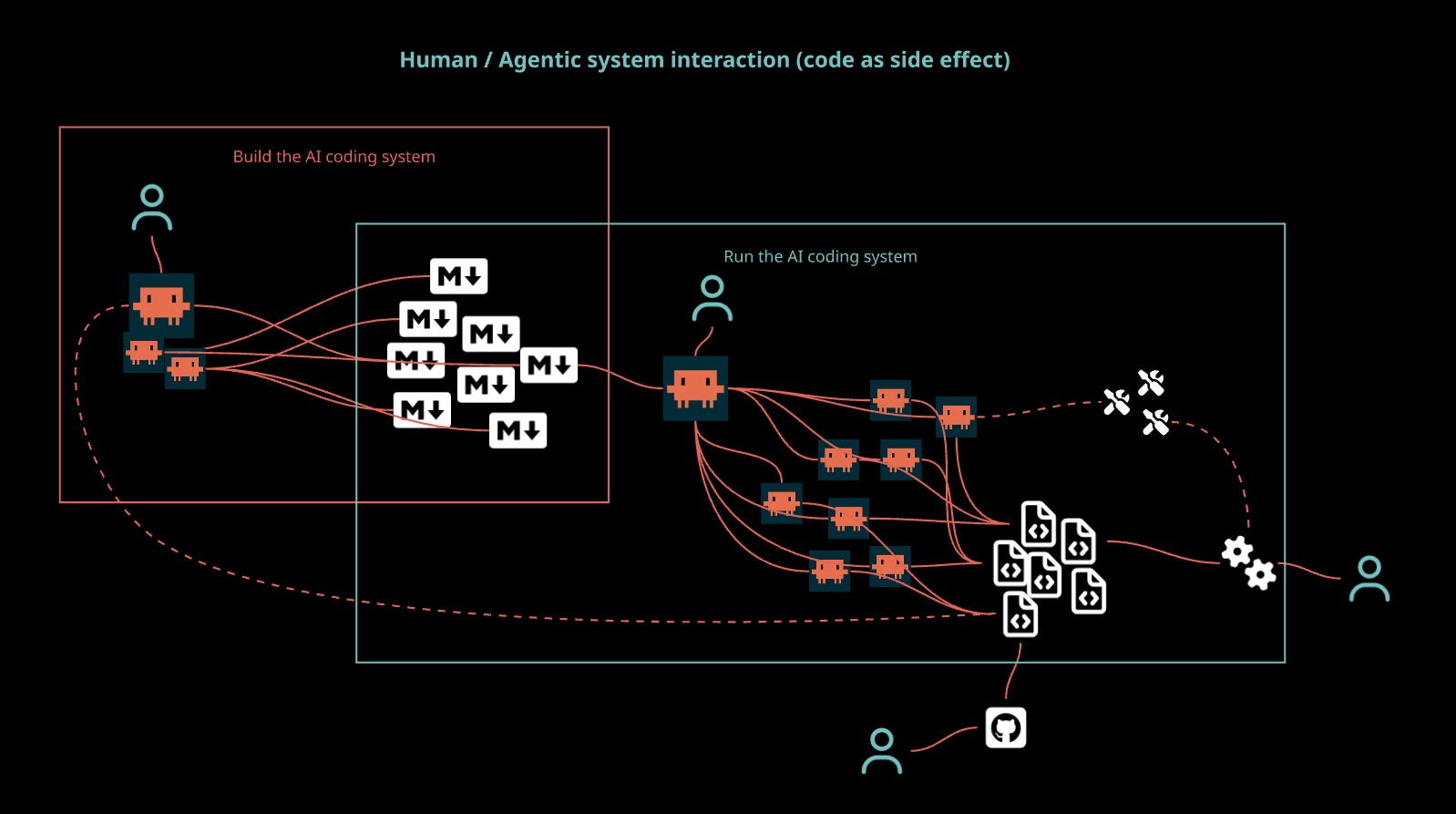
First, you work with Claude Code to design and build a custom agentic system of skills, agents, templates, workflows, and supporting docs — all based on your unique needs and the design principles you value.
Then, you install the agentic system into your target codebase and activate it through Claude Code, watching it autonomously run through the phases and cycles built into the system, generating spec documents that go through human alignment rounds before fanning out to implement, review, test and validate.
In the end you have a full repository of code (that you may never look at) along with copious supporting documentation that you look at very closely — plans, learnings, decisions made, behavioral parity checklists and reports against the code, spec, and running system. And naturally you can run the code yourself for first-hand acceptance and validation.
Given this level of process rigor and supporting document fidelity, confidence becomes achievable.
Design Principles
How do you bake confidence into the system? It starts with design principles and values garnered from hard-won insights from working with LLMs, agentic tooling, and Claude Code feature sets, as well as emerging best practices across the industry as a whole. Here are the top 5:
Focus on the specs — the right specs result in the right output, while small errors up front compound and cascade.
Multiple review loops — even the best LLM models make errors and omissions, it is unavoidable. Double-check all work with adversarial agents with fresh contexts and judicial prompts.
Validate or it isn’t real — LLMs are optimistic by nature, patterns appear accurate, but running systems are the only ground truth.
Self-improving — making the same mistake twice is a failure of the system, so capture and spread learnings and decisions.
Resumability — the system should survive a restart (an unexpected crash or a purposeful
/clear) or a hand-off, meaning all context and process state is persisted in the file system and source control.
Additionally, long-standing theoretical foundations apply surprisingly well here. This can be thought of as latent space engineering — “seeding” the LLM to activate pathways that follow desired practices. A few examples:
Shannon’s information theory says precise specs reduce uncertainty — so design skills that produce detailed and tightly-scoped behavioral contracts to reduce the entropy an implementer agent has to resolve.
Fagan’s inspection research says independent reviewers with fresh context catch more defects than the original author — so design the flow so that the code reviewer agent never sees the implementation prompt, only the spec and the output.
The Hayes-Roth blackboard architecture pattern provides a shared learning store so agents can record discoveries mid-process and every subsequent agent benefits.
Sweller’s cognitive load theory lays the foundation for how to scope each implementation agent’s context tightly — one job, minimal inputs, clear outputs.
While these theories were all formed long before LLMs existed and were designed for humans, they actually apply astoundingly well to LLM context window limitations. When you are removed from the layer of code, the structure of the process is your confidence.
The System
You would add as many specialized agents as you need, each with a single role:
An analyzer explores the domain and produces structured analysis.
A designer turns that into architecture and work unit specs.
A plan reviewer checks those specs before anyone code is written to be sure they are accurate.
An implementer writes code for a single work unit spec, following TDD.
A code reviewer evaluates quality with fresh context.
A parity reviewer verifies behavioral equivalence between the implemented code and the specs.
A test engineer writes integration tests between the independent work units.
An acceptance tester runs system-level validation against the running system, ensuring all specs are covered.
An orchestrator skill manages the flow: analyze, design, plan, implement, test, validate — with agent review and human alignment at each phase. The automated flow drops into conversation at key moments — both at checkpoints and dynamically when an agent hits ambiguity. That dialogue allows for understanding and alignment throughout the process.
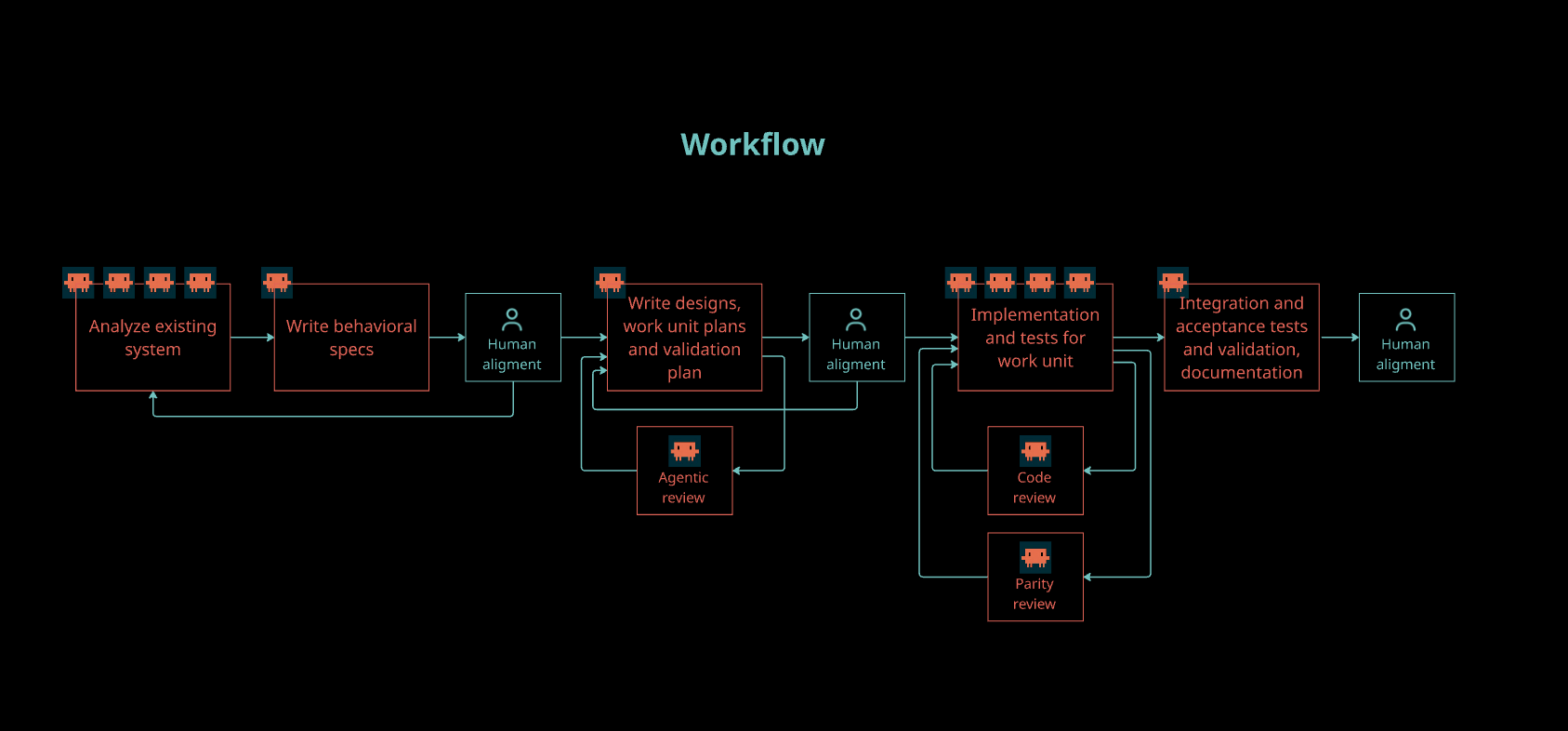
Every agent interaction produces artifacts based on templates:
Behavioral contracts
Architecture and design
Design reviews
Amendments
Work unit level plans
Code reviews
Parity reviews
Validation reports
Lessons learned
Progress audit trail
The paper trail is the confidence. You don’t trust the code because you read it — you trust it because you read every decision that shaped it and every check that validated it against the specs, itself, and the running output.
Perfecting the System
Building a system like this requires iteration. Run it against a well-known quantity, capture failure modes, then chip away at them each iteration until it runs smooth.
When AI writes the code, traditional code review stops being the primary confidence mechanism. What replaces it is process design for a system built on confidence. When you can trust the system, you can trust its outputs.